Control - How to Steer Diffusion Models
On this page, I have compiled several methods to steer the diffusion process. If not otherwise stated, I present the methods as they are used with Stable Diffusion.
Although the mechanisms presented are used in 2D image generation, I assume that they can be used in the generation of other modalities.
I will try to keep this article up to date. If you have any suggestions, please let me know.
Finetune
Cross Attention
In Stable Diffusion (and Imagen/Dalle 2) text prompts are used to condition the image generation. The text prompts are encoded by a text model. The encoding is passed into the diffusion model to a cross-attention layer. The cross-attention layer can also be used to condition on different information. However, adding new conditioning requires retraining.
This is probably not great when you want to combine multiple conditionings as each would likely require its own cross-attention layers.
- increases model size
- adds cross-attention layers
- requires retraining or finetuning
Concatenation
If the conditioning you want to use has the same size as the diffusion model input, you can use concatenation. If it doesn’t, you can still embed it into this shape.
For example, you can train an upsampling model by concatenating (in the channel dimension) the noisy input and a lower-resolution input that is bilinearly upsampled to the input size. For this specific use case, the input size of the model increases from BxCxHxW to Bx2*CxHxW (“Guided-Diffusion Paper”).
Some video diffusion papers applied this method to interpolate frames in the frame/time dimension.
- increases input size in the channel dimension
- requires retraining or finetuning
- can be an alternative to cross-attention
Train a New Model
ControlNet
ControlNet introduces additional control to an existing diffusion model by copying only the downsample layer weights of the diffusion U-Net. The original weights are frozen and the copied weights are connected to the original model via a “zero convolution” in the upsample part of the U-Net.
The “zero convolution” is simply a convolution with all weights set to zero. This way, the original model is not affected by the copied weights at the beginning of training. The zero weights become non-zero while training ControlNet.
Before passing conditioning information through the copied layers, it is encoded by an additional encoder model.
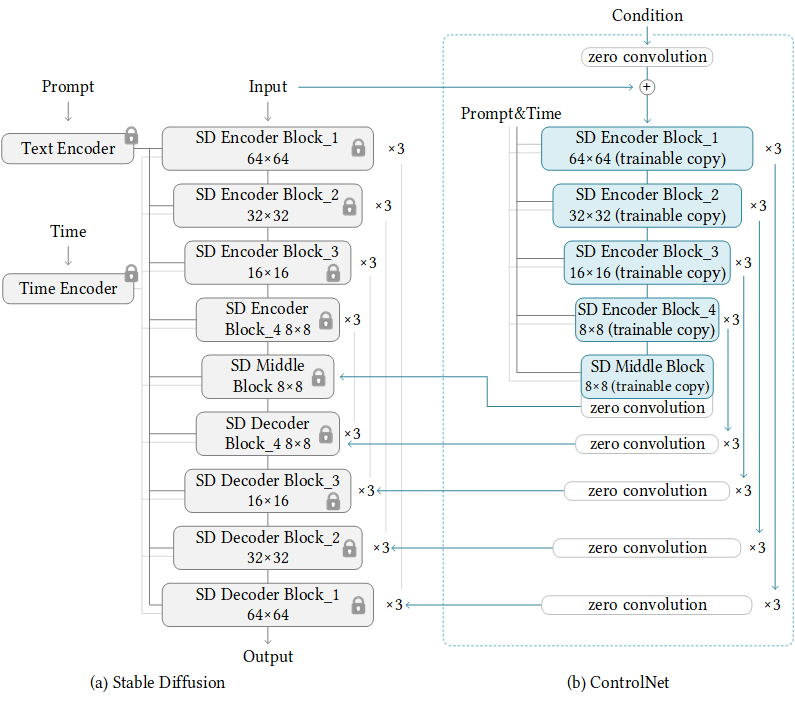
- increases memory size (23%) and time (34%) for training
- not lightweight, but not as heavy as cross-attention or concatenation on conditioning information
T2I-Adapter
T2I-Adapter is more lightweight than ControlNet. It does not finetune any of the original weights. Instead, it only injects conditioning information to the encoder/downsample layers of the diffusion U-Net by addition.
The conditioning (512x512) is brought to the size of the first encoder layer (64x64) by pixel unshuffling which seems to move some pixel data of an image to the channel dimension. Then it is encoded by a small multilayer convolutional network to the size of each U-Net layer.
The biggest advantage of T2I over ControlNet I see is composability. You can use multiple conditionings by simply adding them together.
An interesting application of T2I-Adapter in the paper is sequential editing where a T2I-Adapter is applied to an image multiple times.

- lightweight (300MB)
- composability
No Training Required
Gradient-Based Guidance -> CLIP Guidance
This method uses the gradients of a distance function to steer image generation.
Concretely: CLIP encodes both text and image into a shared vector space. In CLIP guidance, a difference between the generated image and the text prompt is calculated. From this difference, gradients are calculated and added to the current noise prediction.
Simplified code from diffusers:
loss = spherical_dist_loss(image_embeddings_clip, text_embeddings_clip).mean() * clip_guidance_scale
grads = -torch.autograd.grad(loss, latents)[0]
noise_pred = noise_pred_original - torch.sqrt(beta_prod_t) * grads
I have used this approach together with a face recognition model to steer generation towards
generating faces that look like a groundtruth face.
The generated face was very similar to the ground truth face but not perfect. By itself, it is probably not enough. The authors of DifFace use this method combined with a learned face conditioning to improve the generation result.
This is generated me:

- no increase in model size
- no retraining
- you could apply multiple conditionings this way
Other applications:
- As far as I know, this has also been used to enforce depth in generated images by using a MiDaS model.
- It has also been used to generate 3D objects without any training data!
Partial Diffusion (Inpainting/Outpainting)
This method is limited to inpainting and outpainting based on existing image areas. It works by only using random noise for the new areas to generate and using noised original image areas for the areas to keep.
Example:
noisy_guidance_latents = scheduler.add_noise(original_image_latents, guidance_noise, timestep)
latent_model_input = latent_model_input * (1 - mask) + noisy_guidance_latents * mask
noise_pred = self.unet(latent_model_input, timestep, encoder_hidden_states=text_embeddings,).sample
This method can also be used for video diffusion to generate new frames based on previous ones. The advantage is that retraining is not necessary.
Final Thoughts
It seems like there is a push towards a decoupling of conditioning and generative model.
Although in Stable Diffusion the text conditioning was still trained jointly via cross-attention, I could imagine future image generative models train that conditioning separately. This would make it possible to switch text encoders without retraining the whole diffusion model and the diffusion model would be more lightweight with cross-attention being removed.
On this page, I have compiled several methods to steer the diffusion process. If not otherwise stated, I present the methods as they are used with Stable Diffusion.
Although the mechanisms presented are used in 2D image generation, I assume that they can be used in the generation of other modalities.
I will try to keep this article up to date. If you have any suggestions, please let me know.
Finetune
Cross Attention
In Stable Diffusion (and Imagen/Dalle 2) text prompts are used to condition the image generation. The text prompts are encoded by a text model. The encoding is passed into the diffusion model to a cross-attention layer. The cross-attention layer can also be used to condition on different information. However, adding new conditioning requires retraining.
This is probably not great when you want to combine multiple conditionings as each would likely require its own cross-attention layers.
- increases model size
- adds cross-attention layers
- requires retraining or finetuning
Concatenation
If the conditioning you want to use has the same size as the diffusion model input, you can use concatenation. If it doesn’t, you can still embed it into this shape.
For example, you can train an upsampling model by concatenating (in the channel dimension) the noisy input and a lower-resolution input that is bilinearly upsampled to the input size. For this specific use case, the input size of the model increases from BxCxHxW to Bx2*CxHxW (“Guided-Diffusion Paper”).
Some video diffusion papers applied this method to interpolate frames in the frame/time dimension.
- increases input size in the channel dimension
- requires retraining or finetuning
- can be an alternative to cross-attention
Train a New Model
ControlNet
ControlNet introduces additional control to an existing diffusion model by copying only the downsample layer weights of the diffusion U-Net. The original weights are frozen and the copied weights are connected to the original model via a “zero convolution” in the upsample part of the U-Net.
The “zero convolution” is simply a convolution with all weights set to zero. This way, the original model is not affected by the copied weights at the beginning of training. The zero weights become non-zero while training ControlNet.
Before passing conditioning information through the copied layers, it is encoded by an additional encoder model.
- increases memory size (23%) and time (34%) for training
- not lightweight, but not as heavy as cross-attention or concatenation on conditioning information
T2I-Adapter
T2I-Adapter is more lightweight than ControlNet. It does not finetune any of the original weights. Instead, it only injects conditioning information to the encoder/downsample layers of the diffusion U-Net by addition.
The conditioning (512x512) is brought to the size of the first encoder layer (64x64) by pixel unshuffling which seems to move some pixel data of an image to the channel dimension. Then it is encoded by a small multilayer convolutional network to the size of each U-Net layer.
The biggest advantage of T2I over ControlNet I see is composability. You can use multiple conditionings by simply adding them together.
An interesting application of T2I-Adapter in the paper is sequential editing where a T2I-Adapter is applied to an image multiple times.
- lightweight (300MB)
- composability
No Training Required
Gradient-Based Guidance -> CLIP Guidance
This method uses the gradients of a distance function to steer image generation.
Concretely: CLIP encodes both text and image into a shared vector space. In CLIP guidance, a difference between the generated image and the text prompt is calculated. From this difference, gradients are calculated and added to the current noise prediction.
Simplified code from diffusers:
loss = spherical_dist_loss(image_embeddings_clip, text_embeddings_clip).mean() * clip_guidance_scale
grads = -torch.autograd.grad(loss, latents)[0]
noise_pred = noise_pred_original - torch.sqrt(beta_prod_t) * grads
I have used this approach together with a face recognition model to steer generation towards generating faces that look like a groundtruth face. The generated face was very similar to the ground truth face but not perfect. By itself, it is probably not enough. The authors of DifFace use this method combined with a learned face conditioning to improve the generation result.
This is generated me:
- no increase in model size
- no retraining
- you could apply multiple conditionings this way
Other applications:
- As far as I know, this has also been used to enforce depth in generated images by using a MiDaS model.
- It has also been used to generate 3D objects without any training data!
Partial Diffusion (Inpainting/Outpainting)
This method is limited to inpainting and outpainting based on existing image areas. It works by only using random noise for the new areas to generate and using noised original image areas for the areas to keep.
Example:
noisy_guidance_latents = scheduler.add_noise(original_image_latents, guidance_noise, timestep)
latent_model_input = latent_model_input * (1 - mask) + noisy_guidance_latents * mask
noise_pred = self.unet(latent_model_input, timestep, encoder_hidden_states=text_embeddings,).sample
This method can also be used for video diffusion to generate new frames based on previous ones. The advantage is that retraining is not necessary.
Final Thoughts
It seems like there is a push towards a decoupling of conditioning and generative model. Although in Stable Diffusion the text conditioning was still trained jointly via cross-attention, I could imagine future image generative models train that conditioning separately. This would make it possible to switch text encoders without retraining the whole diffusion model and the diffusion model would be more lightweight with cross-attention being removed.